


Ce premier chapitre est le chapitre technique du livre. Il est divisé en deux parties, la première présente les bases du fonctionnement d’Internet qu’il est nécessaire de lire pour comprendre où est le pouvoir. La seconde partie introduit la sécurité avec quelques équations mathématiques afin de démistifier la cryotographie. Cette seconde partie n’est pas nécessaire pour la suite du livre mais il est bon pour un internaute d’avoir quelques notions de sécurité.
La grande force d’Internet est de permettre aux machines de communiquer entre elles. Historiquement d’autres systèmes ont permis la même chose, mais avec Internet la sauce a pris.
Aujourd’hui l’internaute sait qu’il peut communiquer avec 1 milliard de personnes grâce à Internet et, a priori, peu lui importe de savoir comment. Mais pour celui qui désire comprendre les enjeux liés à Internet, tant en interne lorsqu’on parle de gouvernance qu’en externe lorsqu’on compare la téléphonie sur IP à la téléphonie classique par exemple, il est nécessaire de connaître les bases techniques sur lesquelles Internet est construit.
Dans son principe, la mécanique d’Internet est simple. Elle est basée sur deux notions :
Le premier point souligne le fait que toutes les machines connectées à Internet parlent la langue informatique commune qu’est TCP/IP2. Outre l’aspect d’une langue commune, l’utilisation de TCP/IP impose une numérotation unique des machines, comme il existe une numérotation des téléphones. Cette numérotation est appelée l’adresse IP et se présente sous la forme de 4 nombres inférieurs à 256 séparés par des points comme 134.157.1.12.
Ainsi deux ordinateurs respectant le protocole TCP/IP peuvent se contacter et communiquer si il existe une liaison entre eux.
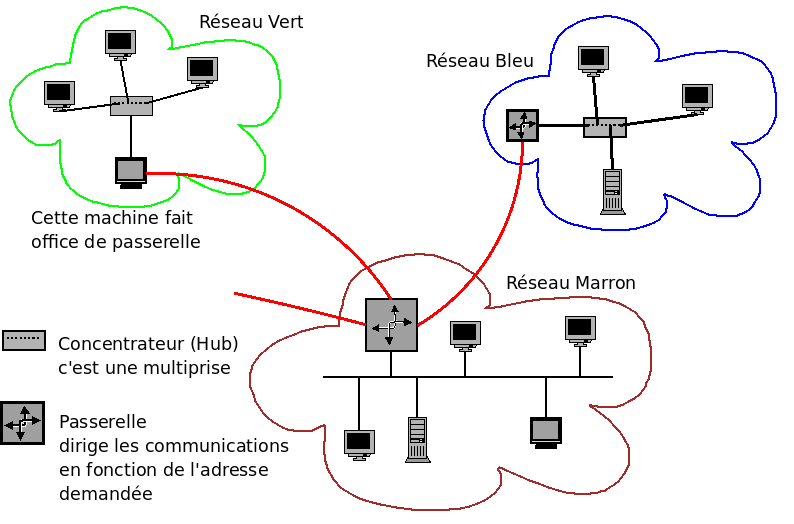
Le second point souligne la structure d’Internet : Internet est une interconnexion de réseaux indépendants, cf figure 1.1. L’internaute à la maison est sur le réseau de son fournisseur d’accès, réseau Vert, et au travail, il est sur le réseau de son entreprise, réseau Bleu. S’il peut se connecter de chez lui au travail, c’est qu’il existe une connexion directe ou indirecte entre ces deux réseaux.
Figure 1.1: Des réseaux interconnectés.
La connexion entre les réseaux passe par des machines spéciales très importantes puisque permettant l’accès aux autre réseaux donc à Internet. Il s’agit des passerelles.
Parfois une machine fait partie d’un réseau qui, lui-même, fait parti d’un gros réseau lequel est relié au reste d’Internet. Ainsi avec le même dessin, les réseaux Vert et Bleu peuvent faire partie du réseau Marron, le réseau Marron étant alors relié au reste d’Internet. C’est souvent le cas dans les réseaux d’entreprise où chaque département a son réseau (Bleu ou Vert) mais doit passer par celui du service informatique (Marron) pour sortir sur Internet.
On retrouve cette notion de sous-réseaux au niveau de l’adresse IP dans l’ordre des 4 nombres. Le premier nombre indique une zone, le second une sous-zone... comme 33 1 42 37 xx xx indique que ce téléphone est en France, dans la région parisienne, à coté de la Croix de Berny (237 étant BER). Mais la comparaison se limite là car l’adressage IP est plus souple, les sous-réseaux n’ayant pas obligatoirement le même préfixe que le réseau auquel ils appartiennent et surtout l’adresse IP n’est pas géographique. D’ailleurs l’attribution des numéros de téléphone aussi a évoluée est n’est plus basée sur la position géographique.
| [H]
Le danger de l’analogie avec le téléphone où l’on constate au passage une trace des dégâts du SMS. B1gron: jve te tracé ac ton ip
Nonoeil: Cool.
B1gron: tu va voir
Nonoeil: Oui. Je vais voir, comme tu dis.
B1gron: put1 sa marche pa!!! ta 1 brouyeur????
Nonoeil: Mais qu'est-ce qu'il dit, l'autre ? Qu'est-ce qui ne marche pas ?
B1gron: sa sonne mm pa che toi
Nonoeil: ça sonne ? Je suis au boulot là, tu vas tomber sur le Central,
si t'appelles, mon rigolo
B1gron: ok alor le central a 1 brouilleur
Nonoeil: le central a ce qu'il veut en même temps
B1gron: jvé tosser cher a coze de ses coneries
Nonoeil: Ouais ouais. Si tu le dis !
Myrdène: Mais attends... T'as composé son numéro IP sur ton portable, B1gron ?
B1gron: ui pk???
source : Les perles d’IRC, www.bashfr.org |
Ainsi une entreprise connue possède les adresses IP qui commencent par 129.42. Il est probable qu’elle a distribué à ses départements des sous-zones comme 129.42.2.xxx pour le département Vert, 129.42.3.xxx pour le Bleu etc...
Si le département Bleu s’achète une connexion directe vers Internet qui ne passe pas par le réseau Marron, alors cela lui offre deux façons de se connecter à Internet mais il est fort probable que les responsables du réseau n’apprécient guère car ils ne pourront plus filtrer toutes les communications entre l’entreprise et Internet ce qui rendra d’autant plus difficile la lutte contre le piratage.
| [H] Des adresses à usage privé Comment a-t-on une adresse IP ? En la demandant à celui qui vous fournit la connexion à son réseau. Il vous donnera une adresse parmi celles qui lui ont été attribuées. Vous pouvez aussi utiliser, sans rien demander, des adresses réservées à usage interne et donc interdites sur Internet. Il s’agit de :
|
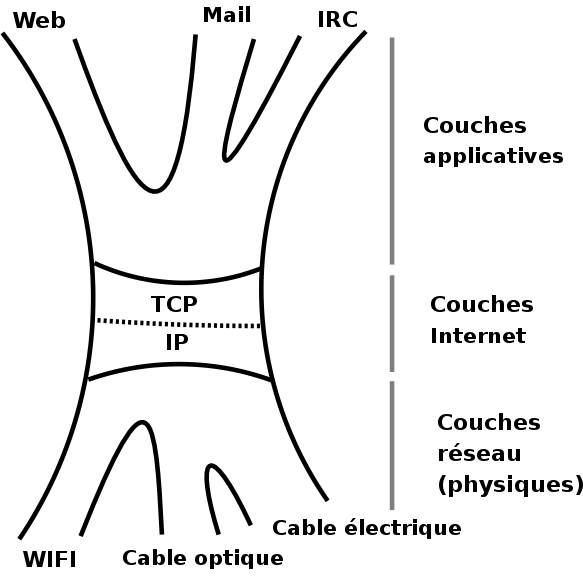
TCP/IP, le protocole d’Internet Afin de simplifier le travail de programmation, les informaticiens ont découpé les communications, entre deux machines ou entre deux programmes, en couches avec le principe que chaque couche communique seulement avec les deux couches l’encadrant. Le modèle de référence des informaticiens fait intervenir 7 couches allant de la couche physique, comment transmettre des 0 et des 1 avec du courant électrique, à la couche applicative sur laquelle se branche les programmes comme un navigateur ou un lecteur de mail. Internet réduit le nombre de couches mais le principe reste le même. Il impose seulement d’utiliser le tronc commun que sont les couches TCP et IP. C’est la raison pour laquelle on associe Internet au protocole TCP/IP.
Ainsi les supports physiques et leur protocole peuvent varier sans avoir d’impact sur la compatibilité Internet. On peut être sur Internet avec une connexion Wifi comme avec une connexion sur un câble électrique ou optique. Cela permet aussi aux applications de définir les protocoles qu’elles désirent tant qu’in fine leur couches applicatives peuvent se raccorder à TCP3. D’où la possibilité de créer toutes les applications imaginables. |
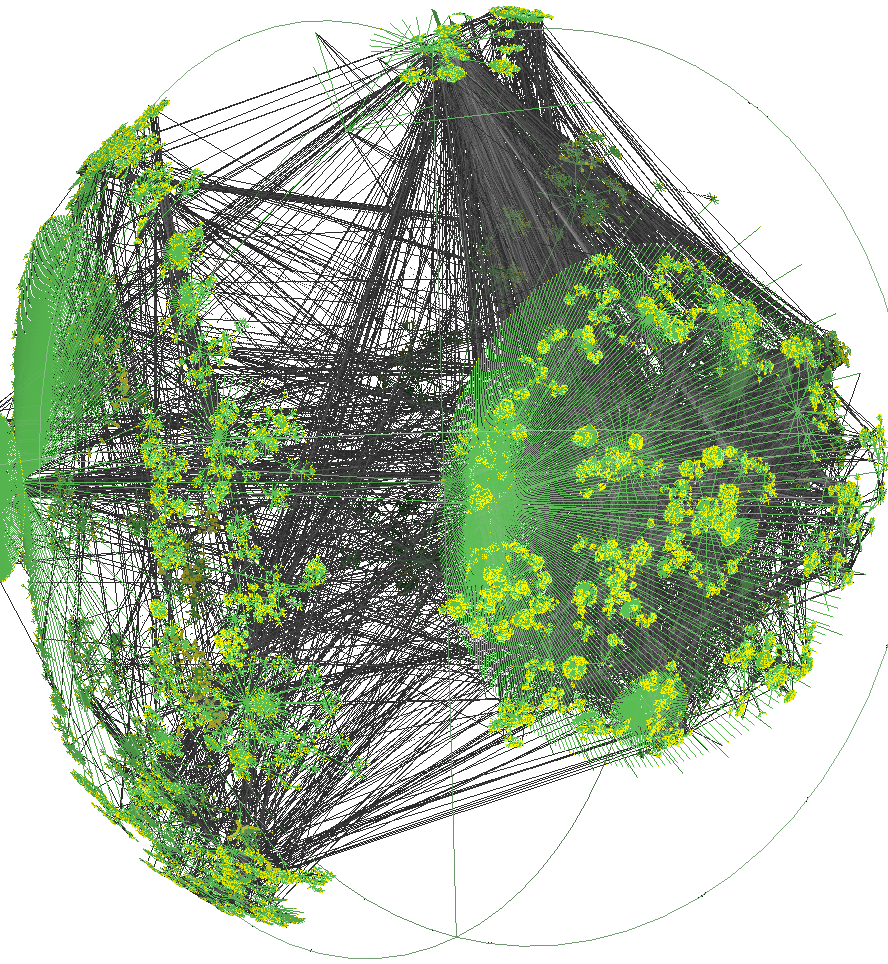
D’un point de vue topologique, Internet n’est que la duplication en millions d’exemplaires de la figure 1.1. Pour que l’image globale soit correcte, il faut détecter quels réseaux sont reliés à quels réseaux, ce qu’a fait sur une partie d’Internet CAIDA en 2001 en analysant 535 000 nœuds d’Internet et plus de 600 000 connexions, cf figure 1.3. On retrouve le schéma de l’entreprise à une plus grande échelle, celle des cablo-opérateurs4, mais avec un plus grand nombre de sous-réseaux.
Figure 1.3: Une partie d’Internet vue par le logiciel Walrus source : CAIDA, mars 2001
Que l’on envoie un mail à une machine distante ou que l’on récupère une page web sur une machine distante, le principe est le même : l’information est découpée en paquets de données et relayée de réseaux en réseaux.
La détection des réseaux et de leur interconnexion peut se faire simplement à l’aide de la commande traceroute, mais aussi par le Web à partir de machines qui offrent ce service, cf http://www.traceroute.org/. Ce programme permet de suivre la route d’un chemin entre deux machines d’Internet. Si l’affichage produit peut sembler abscons au premier abord, il est en fait relativement simple : chaque ligne représente une machine par laquelle passe le message.
Outre le joli dessin page ??, ce type de commande permet surtout de connaître son environnement et de connaître la qualité de sa connexion à Internet ou au moins aux nœuds d’Internet que l’on considère le plus important.
Dans l’exemple qui suit, la connexion est établie depuis Jussieu vers le MIT utilise les réseaux universitaires :
(mendel)../home/ricou>traceroute www.mit.edu traceroute to www.mit.edu (18.7.22.83), 30 hops max, 40 byte packets 1 134.157.204.126 (134.157.204.126) 1.089 ms 1.159 ms 0.971 ms 2 cr-jussieu.rap.prd.fr (195.221.126.49) 2.728 ms 11.658 ms 2.525 ms 3 gw-rap.rap.prd.fr (195.221.126.78) 2.317 ms 3.238 ms 2.225 ms 4 jussieu-g0-1-165.cssi.renater.fr (193.51.181.102) 1.981 ms 2.159 ms 2.119 ms 5 nri-c-pos2-0.cssi.renater.fr (193.51.180.158) 2.535 ms 2.55 ms 3.054 ms 6 nri-d-g6-0-0.cssi.renater.fr (193.51.179.37) 1.977 ms 3.465 ms 2.224 ms 7 renater-10G.fr1.fr.geant.net (62.40.103.161) 2.454 ms 3.003 ms 2.814 ms 8 fr.uk1.uk.geant.net (62.40.96.90) 10.002 ms 10.814 ms 9.274 ms 9 uk.ny1.ny.geant.net (62.40.96.169) 78.124 ms 78.424 ms 78.166 ms 10 esnet-gw.ny1.ny.geant.net (62.40.105.26) 116.806 ms 88.891 ms 78.344 ms 11 198.124.216.158 (198.124.216.158) 78.261 ms 86.282 ms 95.795 ms 12 nox230gw1-PO-9-1-NoX-NOX.nox.org (192.5.89.9) 83.425 ms 83.591 ms 83.412 ms 13 nox230gw1-PEER-NoX-MIT-192-5-89-90.nox.org (192.5.89.90) 83.675 ms 83.745 ms 83.75 ms 14 B24-RTR-3-BACKBONE.MIT.EDU (18.168.0.26) 83.767 ms 86.358 ms 83.427 ms 15 WWW.MIT.EDU (18.7.22.83) 85.26 ms 85.565 ms 85.304 ms
Un essai fait d’une machine chez un fournisseur d’accès commercial français vers une université française fera apparaître la machine passerelle renater.sfinx.tm.fr qui sert de passerelle entre Renater et les réseaux commerciaux. Elle est située dans le GIX5 parisien nommé SFINX qui permet à tous les opérateurs Internet de se relier entre eux suivant leurs accords, dit accords de peering.
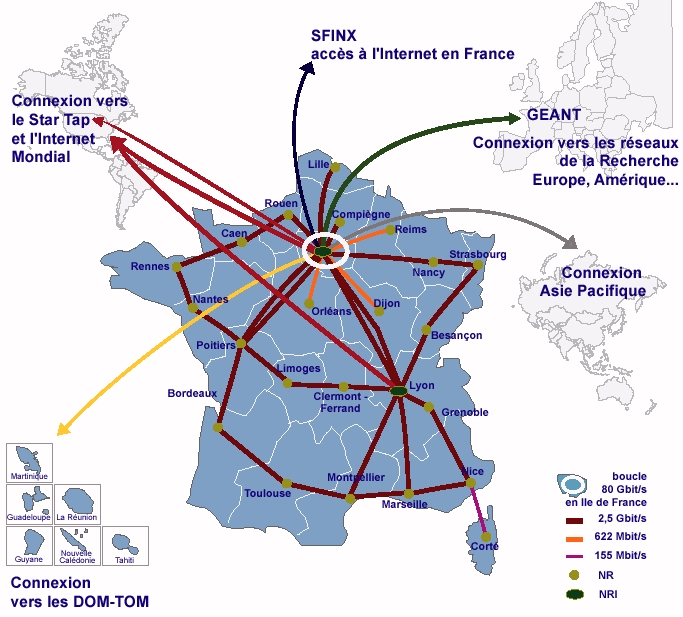
Essayons de comprendre le chemin suivi par notre paquet IP entre Jussieu et le MIT. Le premier intermédiaire que notre message va rencontrer est la passerelle de notre réseau. Son adresse IP est 134.157.204.126 comme on le voit sur la ligne numérotée 1. De là on rejoint l’interconnexion entre Jussieu et le RAP, réseau académique parisien, en 2, pour entrer sur le réseau universitaire français, Renater, en 4, cf figure 1.4.
Figure 1.4: Renater, le réseau universitaire français source : Renater, 2004
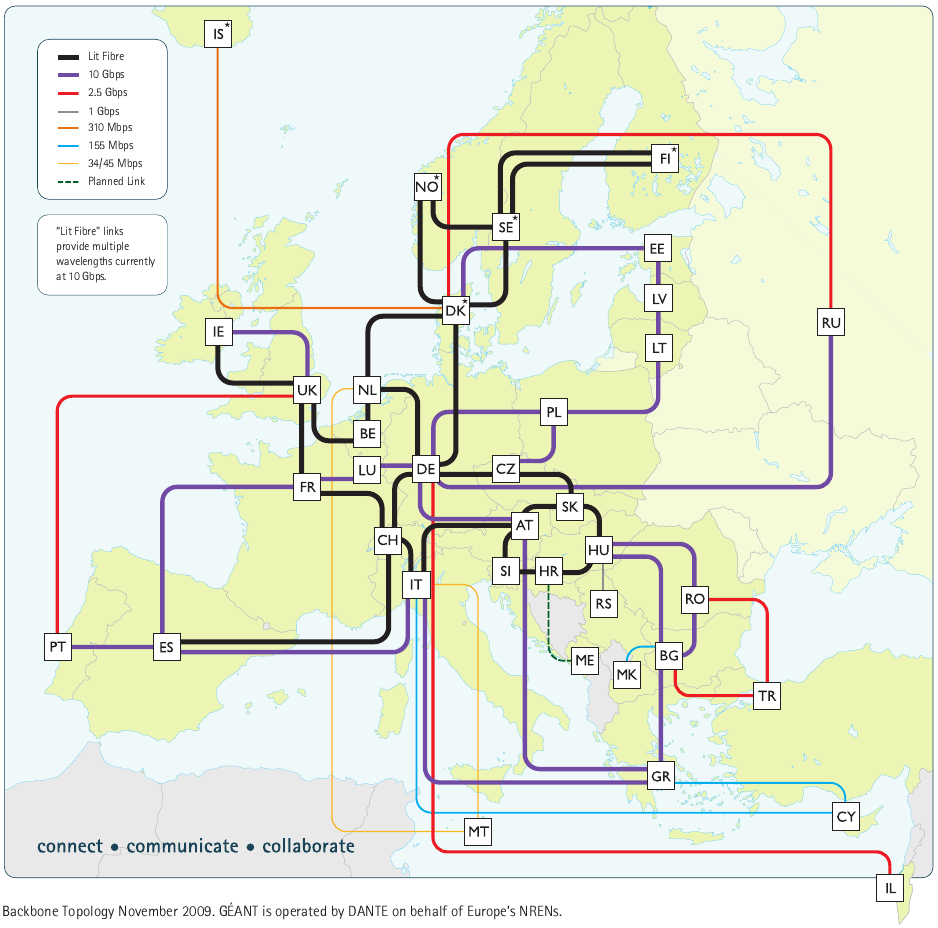
On passe de Renater à Géant, le réseau universitaire européen, en 7, qui nous envoie en Angleterre, en 8, d’où on va à New-York rejoindre Internet 2, en 9 et 10, cf figures 1.5 et 1.6.
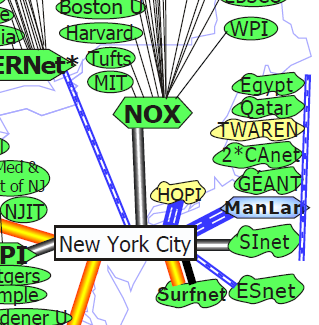
De là on passe sur NOX, le réseau de la Nouvelle Angleterre, en 12 et 13, pour atteindre le réseau du MIT, en 14, et enfin le serveur web www.mit.edu, en 15, cf figure 1.6.
Figure 1.5: Géant, le réseau universitaire européen source : Géant, 2009
Figure 1.6: L’interconnexion entre Géant, Internet 2 et NOX pour arriver au MIT source : Internet 2, 2005
Sachant que le débit entre deux machines est celui du nœud le plus faible, si un réseau a un goulot d’étranglement en un point, cela se ressent directement. Aussi il est toujours bon de savoir quels seront vos partenaires principaux et de savoir par quels cablo-opérateurs vous devrez passer. En pratique il faut savoir quels accords6 a votre hébergeur, avec quels cablo-opérateurs et quelle est l’occupation moyenne du réseau.
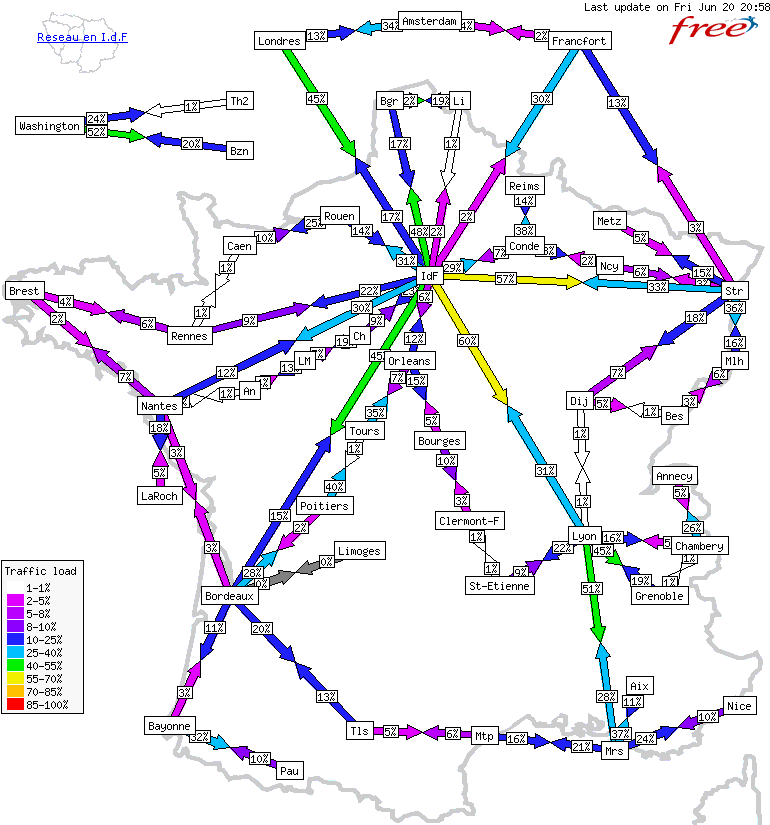
Les cablo-opérateurs les plus sérieux proposent de pouvoir suivre en direct la météo de leur réseau, malheureusement cette information est rare en France.
Concernant les offres pour les particuliers, ce service est tout aussi rare. Heureusement un site web, la grenouille, publie des données récupérées auprès d’abonnés aux différentes offres mais l’information reste limitée.
Figure 1.7: L’état du réseau national chez Free un vendredi soir
Il est aussi possible de faire le travail à la main avec des outils comme bing qui mesurent le débit entre deux machines. Dans l’exemple suivant on teste la connexion entre notre machine à la maison7 et le site web de Yahoo :
# bing 127.0.0.1 www.yahoo.fr ... --- estimated link characteristics --- host bandwidth ms www.euro.yahoo.akadns.net 718.596Kbps 58.753
2ex Si on regarde maintenant le débit entre la machine de notre fournisseur8 d’accès et le site de Yahoo, on a :
# bing 193.252.103.97 www.yahoo.fr ... --- estimated link characteristics --- host bandwidth ms www.euro.yahoo.akadns.net 4.031Mbps 10.116
2ex On constate que le débit passe de 718 Kbits par seconde à 4 031 Kbits par seconde ce qui montre que le goulot d’étranglement est la connexion entre la machine à la maison et la machine de notre fournisseur d’accès.
les machines n’avaient que des numéros, puis devant la croissance du nombre de machines, on a créé un système pour nommer les machines. Cela consistait à avoir sur sa machine un fichier avec les noms et adresses IP de toutes les machines d’Internet. Puis le nombre de machine est devenu trop important et variait trop vite pour garder ce fichier à jour sur toutes les machines. Aussi on a créé un service appelé Domain Name System, DNS, qu’on interroge pour connaître l’adresse IP d’une machine dont on connaît le nom.
|
L’archéologie des noms de domaines Un ami qui aime consulter les textes de loi de l’Internet que sont les RFC, Request For Comments, a fait cette constatation :
Le DNS tel qu’il est aujourd’hui arrivera seulement en 1984. |
La gestion de ce service, et plus précisément de la racine de son arborescence, est à l’origine de nombreuses controverses touchant le contrôle des noms de domaine et leur vente. Elle a mobilisé et mobilise toujours l’Europe et les États-Unis, chacun cherchant à défendre ses intérêts sans pour autant casser Internet ce qui aurait lieu si plusieurs espaces de nommage se faisaient concurrence9. Actuellement l’espace de nommage, et donc le DNS, est géré au niveau mondial par l’ICANN et aux niveaux nationaux par les pays concernés.
|
Confessions d’un voleur ou l’argent des noms de domaines par Laurent Chemla, co-fondateur de la société Gandi Je vends des noms de domaines sur Internet. Un peu d’histoire et de technique sont nécessaires pour comprendre à quel point je suis un voleur. Un nom de domaine, c’est ce qui sert à identifier un ordinateur sur Internet. Quand on vous propose d’aller visiter www.machinchose.org on vous indique un nom d’ordinateur (www) qui se trouve dans le domaine « machinchose.org » et qui contient ces informations que vous pouvez consulter sur le Web. Sans un nom de ce genre, un ordinateur ne peut être consulté qu’en utilisant un numéro, tel que par exemple 212.73.209.251. C’est nettement moins parlant et beaucoup plus difficile à mémoriser. Alors pour simplifier on donne des noms aux ordinateurs qui contiennent de l’information publique. Ce qui nécessite, bien sûr, une base de données qui soit capable de retrouver un numéro à partir d’un nom. Et que cette base soit unique et accessible de n’importe où. Pendant des années, ce système a fonctionné grace à un organisme de droit public financé par le gouvernement américain. L’Internic (c’était le nom de cet organisme) se chargeait de faire fonctionner la base de donnée, et chacun pouvait y ajouter le nom de domaine de son choix, gratuitement, selon la règle du « 1er arrivé 1er servi ». Puis vint le temps de l’ouverture d’Internet au grand public (1994), et la fin des subventions gouvernementales au profit du seul marché. Et là, surprise: une agence publique (qui gérait gratuitement ce qu’il faut bien appeler une ressource mondiale unique) fut transformée en entreprise commerciale (Network Solutions Inc, ou NSI), sans que quiconque s’en émeuve particulièrement, et se mit à vendre 50$ par an (puis 35$ par an dans un fantastique élan de générosité) ce qui était totalement gratuit peu de temps avant. Et pour son seul profit. Je dois vous livrer un chiffre qui, s’il n’est pas confidentiel, mérite cependant le détour : le coût réel de l’enregistrement d’un nom dans la base de données mondiale, y compris le coût de fonctionnement d’une telle base, a été évalué il y a deux ans à 0,30$. Des chiffres comme ça, je pourrais en donner beaucoup. Je pourrais dire par exemple qu’en estimant le nombre de domaines enregistrés par NSI à une moyenne mensuelle de 40.000, son bénéfice sur les 5 dernières années tourne autour des 80 millions de dollars. Et encore ce chiffre est-il une estimation basse, quand on sait que NSI vient d’être racheté par une autre Net-Entreprise pour la modique somme de 21 milliards de dollars. Et pourtant, NSI vend du vent, tout comme moi. En fait, nous vendons le même vent. source : Extrait d’un article publié dans le journal Le Monde en avril 2000 et disponible dans son intégralité sur http://www.chemla.org/textes/voleur.html. |
Internet étant un ensemble de réseaux, il faut une méthode pour nommer les sous-réseaux et y trouver une machine. Pour cela les réseaux et les machines ont des adresses classées dans un système d’arborescence.
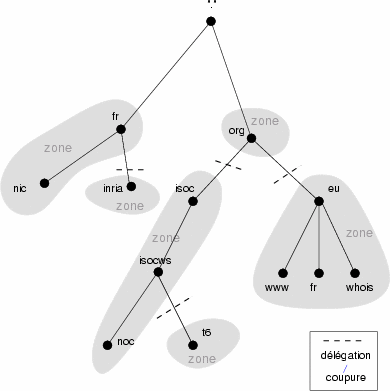
Figure 1.8: Une toute petite partie de l’arborescence des noms de domaines
La terminaison la plus à droite sur ce dessin est la machine whois.eu.org.. Logiquement le nom devrait se lire de droite à gauche avec au début la racine que l’on nomme “.”10 :
Cette machine appartient au domaine eu.org, domaine qui lui même appartient au domaine .org.
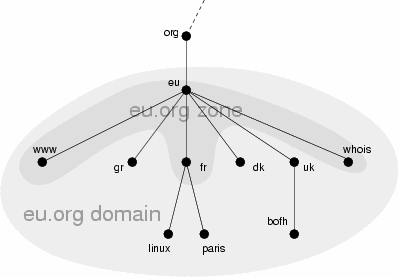
On imagine bien qu’il ne serait pas gérable que chaque machine soit nommée par une seule autorité ne serait-ce que pour des raisons de réactivité et de contrôle. Aussi le nommage d’Internet se base sur un système de délégation de zone. Ainsi .org à délégué la gestion de .eu.org ce qui fait que .eu.org est une zone indépendante de la zone .org.
La figure 1.9 montre comment le domaine eu.org délègue les sous domaines gr.eu.org ou dk.eu.org mais conserve la gestion du sous domaine fr.eu.org et des machines www.eu.org et whois.eu.org.
Il existe donc :
On comprend ainsi pourquoi le propriétaire d’un domaine, comme .fr, ne peut être tenu responsable de ce qu’on trouve sur un serveur web hors de sa zone, comme www.tf1.fr par exemple.
Par contre, techniquement parlant, il peut toujours retirer la délégation de zone et donc fermer le domaine tf1.fr. De même le gestionnaire du point final, les États-Unis, peut fermer .com ou .fr.
Figure 1.9: Délégation de zone
| [H]
eu.org, des domaines gratuits L’exemple eu.org est d’autant plus intéressant que ce domaine délègue gratuitement des sous domaines c.a.d. que si vous désirez avoir un sous domaine comme ricou.eu.org11, il suffit de le demander sur le site web www.eu.org. Cela demande bien sûr de savoir gérer un sous domaine. |
La recherche d’une adresse IP est l’opération initiale pour chaque connexion dès lors que l’on initie la connexion avec le nom de la machine et non son adresse IP. Pour faire la correspondance nom/adresse IP, vous devez avoir indiqué à votre machine l’adresse d’un “Serveur de nom", ou serveur DNSdns. Si tel n’est pas le cas vous ne pourrez plus vous connecter aux autres machines d’Internet, sauf en donnant directement leur adresse IP bien sûr.
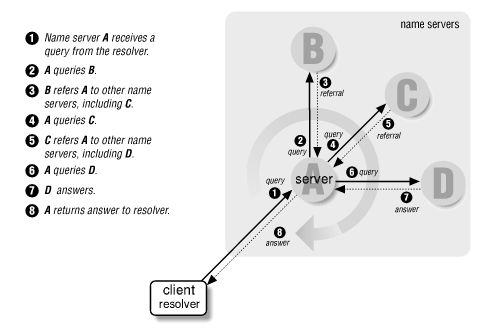
Pour trouver l’adresse IP d’une machine à partir de son nom, votre serveur de nom va lire le nom de la machine de droite à gauche pour savoir à quel autre serveur de nom il pourra demander l’adresse IP s’il ne la connaît pas.
Figure 1.10: Fonctionnement récursif du DNS (illustration extraite du livre DNS & Bind chez O’Reilly)
Supposons que l’on cherche à se connecter sur le serveur web d’un laboratoire de Jussieu : www.ann.jussieu.fr. Notre serveur de nom, A sur la figure 1.10, n’ayant pas en mémoire l’adresse IP12 de cette machine, va devoir la demander au serveur B, qui gère la racine d’Internet .13, lequel renverra sur le serveur C qui gère .fr., qui renverra au serveur D qui gère jussieu.fr. et qui donnera l’adresse IP recherchée 134.157.2.68.
L’importance d’Internet dans notre société ne cesse de croître. Un nombre de plus en plus important de données circulent sur Internet et de plus en plus d’entreprises sont reliées au réseau. En même temps, de plus en plus de machines infectées par des virus servent malgré elles de relais aux attaques informatiques. Les pirates n’ont jamais eu autant de puissance ni autant de victimes à leur disposition.
D’un point de vue technique, Internet actuel a deux vulnérabilités fondamentales : les messages sont transmis sans protection sur le réseau et l’identification de l’interlocuteur qu’il soit individu ou machine est peu fiable.
Ces deux faiblesses peuvent permettre à un pirate d’intercepter des informations qui ne lui sont pas destinées.
À ces deux vulnérabilités il est important d’ajouter l’erreur humaine qui est responsable de bien des mésaventures.
Le protocole de transport des données sur Internet, TCP/IP v.4, ne prévoit pas de protéger les données transportées. Tous les paquets sont transmis en clair. Ainsi toute personne qui contrôle un des ordinateurs par lequel passent les données peut les lire. Par exemple au niveau d’un réseau local, tous les paquets sortant vers Internet doivent passer par une passerelle. Le contrôle de cette machine permet la lecture de tout ce qui va et vient. Toujours sur un réseau local une personne qui est physiquement sur le même fil Ethernet qu’une autre14 peut y détecter le courant qui y passe et donc lire les données.
Ce manque de sécurité devient important lorsqu’on transmet des informations confidentielles comme des mots de passe. Ainsi pour rapatrier son mail depuis un serveur distant, il est usuel d’envoyer son mot de passe qui passe en clair sur le réseau. Sur le web, autant les sites importants comme celui de votre banque protègent sérieusement la phase d’identification, autant cette protection n’est pas appliquée dans de nombreux sites de forum d’où l’importance d’utiliser différents mots de passe suivant le contexte.
Lorsqu’on utilise Internet, on communique toujours avec une machine
distante. Si la connexion est établie avec un programme
qui ne cache pas les données, comme un navigateur,
le flux de données est lisible avec un renifleur de paquets IP comme
le programme tcpdump. Voici ce que l’on peut voir passer si on est sur
le chemin pour écouter :
18:12:23.983918 IP (tos 0x0, ttl 64, id 24337, offset 0, flags [DF], proto: TCP (6), length: 1019) portable18.pmmh.espci.fr.3192 > mg-in-f147.google.com.www: P 1:968(967) ack 1 win 1460 <nop,nop,timestamp 7090623 2265318920> E..._.@.@.i..6Q..U...x.P.Yn....B....r...... .l1.....GET /search?hl=fr&q=piratage+i
où l’on voit que je recherche sur Google une information sur "piratage+i", le "i" étant le début du mot "internet" qui est dans le paquet suivant.
Bien sûr des logiciels existent pour améliorer la présentation voire pour
ne retenir que l’information désirée. Ainsi
le programme dsniff peut récupérer les mots de passe :
[root@diane dsniff-2.2]# ./dsniff -i eth0 dsniff: listening on eth0 ----------------- 09/25/00 18:34:25 tcp hermes.devinci.fr.1415 -> aldebaran.devinci.fr.23 (telnet) test pass_compte ----------------- 09/25/00 18:34:39 tcp hermes.devinci.fr.1416 -> aldebaran.devinci.fr.110 (pop) user test pass pass_pop
Le premier couple login/mot de passe intercepté provient d’une connexion à un ordinateur distant en clair (plus personne ne fait ça maintenant, enfin normalement...), le second d’une connexion à un serveur de mail POP pour y rapatrier son courrier (beaucoups de personnes font toujours ça).
Il est donc important de garder à l’esprit que les données ne sont pas protégées par le réseau et que le travail de protection doit être fait au niveau des applications15 afin que les données ne quittent votre machine que chiffrées. Cela étant il existe une exception lorsque vous utilisez un canal sécurisé comme un tunnel ou un VPN. Dans ce cas tout ce qui passe sur le réseau est protégé mais cela ne marche que pour les machines qui sont reliées par ce canal, cf le transport du mail ci-dessous.
Le protocole utilisé pour diffuser le courrier électronique, SMTP, ne contient pas plus de système de protection des données que les protocoles IP ou TCP (il s’agit de l’empilement de couches informatiques présentées figure 1.2).
Sachant que tout n’est que connexion de machine en machine, le courrier électronique comme les autres services est ouvert à tous si l’on n’utilise pas de moyen de protection. Ainsi, par défaut, le mail
Pour se protéger on peut appliquer diverses solutions qui fonctionneront à différents niveaux :
La solution la plus simple pour éviter qu’un mail ne soit lu par une autre personne que le destinataire est de le chiffrer. Ainsi le mail quitte la machine de l’émetteur illisible et ne sera déchiffré qu’une fois arrivé sur la machine du destinataire. Cette protection est absolue mais demande le plus souvent l’installation d’un greffon17 ainsi que la compréhension du mode d’emploi (cf section 1.2.3). Le jeu en vaut la chandelle, d’autant plus que c’est ce même système qui permet la signature électronique.
Le Web est protégé par l’algorithme de chiffrage SSL18 qui est présent sur les navigateurs les plus courants. Par contre, comme pour tout algorithme de chiffrage, son efficacité est directement liée à son utilisation et à la taille de la clé de codage utilisée.
Ainsi la majorité des pages web ne sont pas chiffrées et donc passent en clair sur le réseau avant d’arriver sur votre ordinateur. Cela veut dire que toute personne qui contrôle les machines intermédiaires peut savoir quelles sont les pages web que vous regardez.
Lorsque vous arrivez sur une page sécurisée, ce qui est visible par une icône en forme de clé ou de cadenas ainsi que dans l’URL qui commence par https, personne ne peut intercepter le contenu si la clé de chiffrement utilisée est dite forte, à savoir contient 128 bits19. Si par contre la clé est plus courte, alors la sécurité est illusoire car trop faible pour résister aux attaques brutales, type d’attaques qui essayent toutes les clés possibles.
En mai 2001, une étude faite par Projetweb, cf tableau 1.1, montrait qu’une majorité de serveurs Web français continuait à utiliser des clés de 40 bits.
Java 0 40 bits 56 bits 128 bits total<128 Banque - Bourse 1,9% 1,9% 65,4% 4,8% 26,0% 74,0% Biens de consommation 0,0% 5,6% 36,1% 2,8% 55,6% 44,4% Culture - Loisirs 0,0% 5,5% 34,1% 3,3% 57,1% 42,9% Maison - Électro-ménager Hifi 1,9% 1,9% 28,8% 7,7% 59,6% 40,4% Total 0,9% 3,8% 43,9% 4,4% 47,0% 53,0%
Tableau 1.1: Niveau de sécurité des serveurs français (étude de ProjetWeb, mai 2001)
Cela n’est heureusement plus le cas aujourd’hui mais n’hésitez pas à cliquer sur le petit cadenas pour vérifier si la protection utilisée est bien SSL 128 bits. Il existe néanmoins un autre risque qui est celui de ne pas être connecté au véritable serveur (cf la section 1.2.4 sur l’authentification).
Quels que soient les outils de sécurité mis en place, il est difficile voire impossible de protéger un système si l’utilisateur autorisé aide le pirate. Cette aide peut aller du mot de passe offerts au pirate à l’installation sur sa machine de programme comprenant des virus. Dans la première catégorie on retrouve les mots de passe trop simples, ceux écrits sur un papier bien visible et enfin ceux donnés innocemment directement au pirate suite à un faux mail d’alerte (méthode dite du phishing, cf l’encart à ce sujet). La seconde méthode va des programmes téléchargés et installés aux greffons et autres extensions ajoutées à ses programmes ou à son système d’exploitation en passant par les pièces attachées des mails qu’on lance sans s’en rendre compte.
Si certaines méthodes techniques, comme la vérification de la sûreté d’un mot de passe, peuvent aider à limiter ce risque humain, il est important de savoir trouver le bon équilibre entre un système trop ouvert, où la moindre faille de l’utilisateur provoque un risque et un système trop coercitif qui sera contournées par les utilisateurs refusant que le système soit un obstacle à leur travail. On notera concernant ce dernier point qu’une étude (voir []) justifie d’un point de vue économique le comportement de ceux qui contournent les mesures de sécurité, l’idée étant qu’un risque dangereux mais rare coûte moins cher à l’entreprise qu’une mesure de protection peu coûteuse en temps mais quotidienne.
La cryptographie est le remède au mal. Elle protège les communications dès lors que votre machine n’est pas infectée, que votre logiciel n’a pas de bug, que vous ne donnez pas vos clés ou mot de passe au pirate...
La cryptographie permet de chiffrer les données, d’en garantir l’intégrité et de les signer.
Le premier point permet
ex
Le second point, la garantie de l’intégrité, permet item d’avoir la certitude qu’un document est complet (contrat, mail, logiciel...) et que personne n’a pu le modifier.
Enfin le dernier point, la signature, permet
ex
Avec la combinaison des trois, je peux envoyer un mail en étant certain que personne d’autre que mon destinataire ne pourra le lire (chiffrage). Mon destinataire aura la certitude que mail vient bien de moi (signature) et qu’il n’a pas été modifié (intégrité). Ainsi je ne pourrai pas contester que je suis à l’origine du message (non-répudiation).
La façon la plus simple de chiffrer un message est de lui appliquer une fonction mathématique. Ainsi Jules César chiffrait ses messages en décalant les lettres de N, ainsi avec N=3, le A devient D. Pour le déchiffrer il suffit d’appliquer la fonction inverse avec la même clé. Bien sûr un bon système de cryptographie propose une fonction inverse qui ne donne rien sans la clé (N dans le cas de Jules César). Ce système est celui de la clé symétrique.
ATTAQUEZ GERGOVIE ↓ DWWDTXHC JHUJRYLH
Figure 1.12: Un message secret de César
Ainsi pour communiquer entre 2 ou 3 personnes il suffit d’avoir une clé commune pour pouvoir communiquer de façon protégée par la suite.
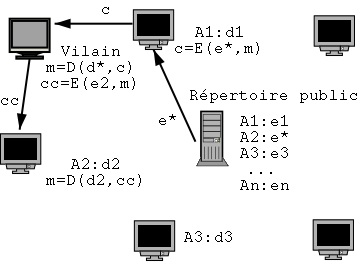
À plus grande échelle, le système dit de tiers de confiance, TDC, (Trusted Third Party en anglais, ou TTP) propose de définir une clé Ki pour chaque utilisateur (voir figure 1.13). Ainsi pour chaque communication, le TDC donne aux 2 utilisateurs une clé de session k pour chiffrer leur communication. Bien sûr cette clé de session est transmise chiffrée avec la clé secrète de l’utilisateur.
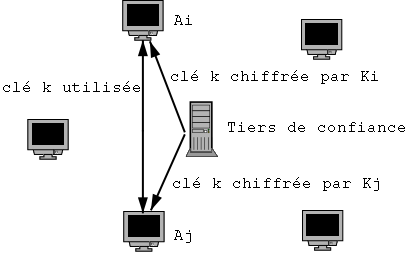
Figure 1.13: Tiers de confiance pour chiffrement symétrique
Ce système de clés symétriques a les avantages suivants :
Les inconvénients sont :
On comprend que la présence du tiers de confiance peut être jugée problématique.
Le système de cryptographie par clé symétrique a été le seul disponible jusqu’après la seconde guerre mondiale, ce qui veut dire que durant la seconde guerre mondiale les clés utilisées devaient être transmises physiquement à travers les théatres d’opération avec tous les risques d’interception possibles lorsqu’on doit traverser les lignes ennemies. Lorsqu’on veut renouveler les clés régulièrement au cas où l’ennemi aurait réussi à les avoir, on en veut à la technologie qui impose cet exercice délicat.
La clé asymétrique corrige ce défaut en permettant de transmettre une clé publiquement tout en gardant une clé secrète pour déchiffrer les messages qu’on reçoit et qui ont été chiffrés avec la clé diffusée publiquement.
Ainsi une clé i est composée d’une clé publique et et d’une clé privée (ei/di), chaque utilisateur ayant la sienne. Le message est chiffré avec la clé publique ei et ne peut être déchiffré qu’avec la clé privée correspondante di.
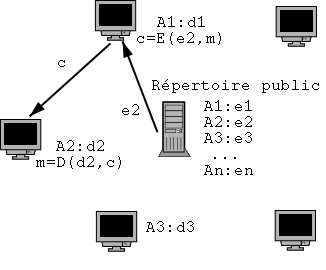
Figure 1.14: Utilisation de clés asymétriques
Les avantages de la méthode sont
Les inconvénients sont :
L’attaque la plus simple contre ce système est de substituer la clé publique d’un utilisateur par celle du pirate et d’intercepter tous les messages. Une fois le message intercepté, le pirate, l’homme au milieu, le décode, le note, puis le recode avec la véritable clé publique du destinataire pour lui envoyer afin qu’il ne détecte pas l’interception.
Figure 1.15: Attaque de l’homme au milieu
La parade, pour ne pas voir son message intercepté, réside dans la fiabilité de la clé publique de son destinataire. Une clé publique est sûre, soit parce que le destinataire vous l’a remise en main propre, soit parce qu’une personne en qui vous avez entièrement confiance vous garantit cette clé publique. Cette personne de confiance peut être un tiers de confiance institutionnel ou une personne dont vous êtes sûr car elle est dans votre liste des personnes de confiance. Dans ce dernier cas on parle de votre réseau de confiance ou Web of trust (cf section 1.2.4).
Sans remonter jusqu’à Jules César, il existe de nombreux algorithmes de cryptographie. Certain sont plus connus que d’autres et leur célébrité est la garantie de leur fiabilité. En effet il est difficile de créer un algorithme de cryptographie solide et seule sa vérification par le plus grand nombre possible de mathématiciens et d’utilisateurs peut offrir une garantie de sécurité.
Historiquement DES, Data Encryption Standard, est le premier standard officiel des États-Unis à destination des entreprises. Il s’agit d’un algorithme de chiffrement à clé symétrique développé par IBM dans les années 70. DES utilise une clé de 56 bits qui, de nos jours, est bien trop faible pour résister aux attaques. Aussi DES ne doit plus être utilisé.
Son premier remplaçant a été Triple DES qui n’est que l’application de DES trois fois avec des clés différentes. Cela permet en effet d’amener la sécurité à un niveau correct mais pour un coût élevé en temps de calcul.
Aussi à la fin des années 90, le gouvernement américain à lancé un concours pour trouver le remplaçant idéal, sûr et peu gourmand en CPU afin de pouvoir l’exécuter sur le processeur d’une carte à puce. Le 2 octobre 2000 le gouvernement américain a annoncé que l’Advanced Encryption Standard, AES, est l’algorithme belge Rijndael.
Figure 1.16: AES expliqué en BD
Ronald Rivest est un cryptologue qui a conçu de nombreux algorithmes de chiffrements symétriques dit à la volée (“stream cipher” – RC4) et par bloc (“block cipher” – RC2 / RC5 / RC6). Parmis ces algorithmes, RC4 est le seul de la famille à être propriétaire (“trade secret”) mais son code a été largement diffusé. RC6 était un des 5 candidats retenus à AES.
Mais l’heure de gloire20 est arrivée avec RSA21. Cet algorithme conçut en 1977 avec Adi Shamir et Len Adleman est le premier algorithme publié22 à clé publique/clé privée (ou asymétrique). Il est toujours très utilisé. Son principe mathématique est expliqué page ??.
Les condensats permettent de garantir l’intégrité d’un document. Il s’agit d’une fonction à sens unique, dite de hachage, qui résume un document en une ligne, le condensat. Cette fonction est telle que si l’on modifie quoi que ce soit dans le document, alors le condensat devient totalement différent. Les condensats les plus connus sont MD5 et SHA-1. Malheureusement ils ont tous les deux été cassés ce qui rend possible la génération d’un autre document qui produit le même condensat. Ces failles sont à l’origine du concours SHA-3, qui à l’instar de l’AES, devrait permettre en 2012 de disposer d’une fonction de hachage sûre et reconnue. En attendant il existe d’autres condensats comme SHA-256, Whirlpool ou Tiger.
md5("Le condensat garantit l'intégrité") = 9fb6e5c02fd664892271ca02e0266457 md5("Le condensat garantit l'intégrite") = d80c680cf92d64cb7830c86fbb2350f7 Seul le é final a changé mais le condensat est totalement différent.
Figure 1.17: Utilisation d’un condensat
L’algorithme RSA est un algorithme de chiffrement à clé publique/clé privée. Il est asymétrique et ne nécessite pas la transmission de la clé permettant le décodage.
L’idée d’un algorithme asymétrique a été proposée par Whitfield Diffie et Martin Hellman dans un article en 1975 et mise en pratique en 1977 par Ronald Rivest, Adi Shamir et Leonard Adleman. James Ellis et Clifford Cocks des services de communication de l’armée anglaise, avaient trouvé cet algorithme quelques années plus tôt mais ne purent le dévoiler pour cause de secret militaire (cf [] et l’histoire présentée par Ellis).
Son principe est relativement simple mais totalement révolutionnaire. On n’imaginait pas jusque là qu’il puisse être possible de décoder un message sans avoir la clé ayant permis de l’encoder. Pour cela chaque utilisateur a
où n, d et e sont des entiers avec les propriétés suivantes :
Ces choix impliquent que ed mod J(n) = 1 où J(n) est la fonction d’Euler sachant que J(n)=(p−1)(q−1) lorsque p et q sont premiers.
En chiffrant un message M à l’aide de sa clé publique (n||e) on a :
| M′ = Me mod n (1.1) |
ce qu’il peut déchiffrer avec sa clé privée (n||d) car
| M′d mod n = (Me mod n)d mod n = Med mod n = Med mod J(n) = M |
En envoyant un message chiffré avec sa clé privée (n||d) on a
| M′ = Md mod n |
que le destinataire peut lire avec la clé publique (n||e) de l’émetteur en calculant M′e mod n.
|
La carte bleue cassée Le 4 mars 2000, le texte suivant tombait dans le forum fr.misc.cryptologie : Petite feuille Maple > pub:=2^320+convert(`90b8aaa8de358e7782e81c7723653be644f7dcc6f816daf46e532b91e84f`,decimal,hex); pub := 2135987035920910082395022704999628797051095341826417406442524165008583957746445088405009... > facteur1:=convert(`c31f7084b75c502caa4d19eb137482aa4cd57aab`, decimal, hex); facteur1 := 1113954325148827987925490175477024844070922844843 > facteur2:=convert(`14fdeda70ce801d9a43289fb8b2e3b447fa4e08ed`, decimal, hex); facteur2 := 1917481702524504439375786268230862180696934189293 > produit:=facteur1*facteur2; produit := 213598703592091008239502270499962879705109534182641740644252416500858395774644508840... > exposant_public:=3; exposant_public := 3 > modulo_div_eucl:=(facteur1-1)*(facteur2-1); modulo_div_eucl := 2135987035920910082395022704999628797051095341823385970414850832581282681302... > essai_rate_exposant_prive:=expand((1+modulo_div_eucl)/3); essai_rate_exposant_prive := 213598703592091008239502270499962879705109534182338597041485083258... > exposant_prive:=expand((1+2*modulo_div_eucl)/3); exposant_prive := 14239913572806067215966818033330858647007302278822573136099005550541884542018... > testnb:=1234; testnb := 1234 > testsignnb:=testnb &^ exposant_prive mod produit; testsignnb := 2235938147775183775641042325450404557899532144626481715236694290974806919234121583... > testverifsignnb:=testsignnb &^exposant_public mod produit; testverifsignnb := 1234 On y trouve les nombres premiers p et q, ici facteur 1 et facteur 2 qui permettent de connaître le module n, ici produit. On voit que l’exposant publique, e, est 3 et après un premier test raté on trouve l’exposant privé d. Pour être sûr que tous ces chiffres sont bons, on chiffre 1234 et on le déchiffre. Ça marche. Ce jour là le grand public voyait en clair la clé RSA à 320 bits qui permet de vérifier l’authenticité d’une carte bleue (voir l’article de Louis Guillou) . Cela indique seulement qu’une carte est authentique et non que l’on connaît le code secret de l’utilisateur, mais cela permet de faire des fausses cartes23 qui tromperont un lecteur non relié aux banques comme celui qu’on présente souvent dans les restaurants (cf le reportage de LCI). C’est cette faiblesse connue des milieux de la cryptographie qu’a utilisé Serge Humpich24. La trouvaille n’est pas extraordinaire car casser une clé de 320 bits n’est plus un exploit depuis le début des années 90. L’exploit réside surtout dans la légèreté du groupement des cartes bleues. |
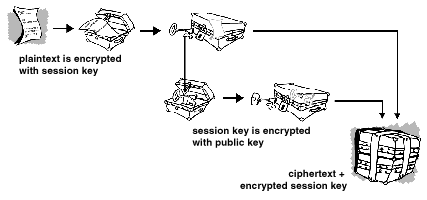
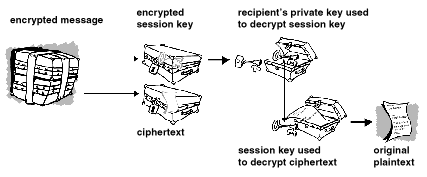
Comme on l’a vu, le courrier est particulièrement vulnérable et la seule façon de le protéger nécessite l’usage de la cryptographie. Actuellement il existe deux principaux logiciels pour chiffrer les mails : PGP pour Pretty Good Privacy remplacé aujourd’hui par GPG, GNU Privacy Guard, et S/Mime. Tous les deux utilisent différents algorithmes de cryptographie pour remplir toutes les conditions nécessaires à la protection du courrier :
ex Pour des raisons de performance, les messages sont donc chiffrés à l’aide d’un système à clé symétrique dite clé de session. Cette clé est elle-même chiffrée avec la clé publique du destinataire, ainsi lui seul pourra la récupérer avec sa clé privée et donc lire le message.
Figure 1.18: Encodage d’un message à l’aide de PGP
Figure 1.19: Décodage d’un message à l’aide de PGP
Pour signer et vérifier l’intégrité du courrier, l’émetteur fait un condensat du courrier et le chiffre avec sa clé publique. Ainsi le destinataire peut générer le condensat du courrier déchiffré et le comparer avec le condensat que lui a envoyé l’émetteur après l’avoir déchiffré avec la clé publique de l’émetteur.
Lorsque GPG est inclu dans votre logiciel de mail, son utilisation est transparente. Son initialisation peut faire peur pour celui qui ne connait rien à la cryptographie puisque qu’on va lui demander de protéger sa clé privée avec un mot de passe et de publier sa clé publique. La publication de la clé publique est la partie la plus sensible puisque mal faite, elle peut permettre l’attaque de l’“homme au milieu”, cf page ??. Il est donc soit nécessaire de la transmettre main dans la main25, soit de la faire signer par une autorité de certification, voir page ??.
Figure 1.20: Carte de visite avec condensat de la clé publique
S/MIME ou GPG sont de plus en plus intégrés dans les lecteurs de courrier. Pour les webmails26 c’est plus rare mais il existe un greffon pour GMail appelé FireGPG.
Outlook et S/MIME GMail et FireGPG
Figure 1.21: Lecteurs de mail et leur outil de cryptographie
Le Web est probablement l’application la plus sensible pour la majorité des internautes. Il est utilisé pour faire ses achats, pour aller gérer son compte bancaire voire pour accéder à des données confidentielles. Aussi il est important qu’il comble les vulnérabilités inhérentes à Internet. Cela est fait avec le protocole TLS (anciennement SSL) qui chiffre toute donnée qui sort de votre navigateur avec une clé de session que ne connait que le serveur avec qui vous communiquez. Ainsi une personne qui intercepte la communication ne comprendra rien.
TLS est automatiquement activé dès qu’on arrive sur une adresse qui commence par https. Les navigateurs soulignent l’aspect sécurisé de la communication avec une icône représentant un cadenas ou une clé.
Si cet aspect est sûr, il reste néanmoins des failles. La plus courante consiste à vous rediriger vers un autre site web qui ressemble trait pour trait à votre site web habituel. Pour éviter cela, un site web sécurisé doit vous envoyer son certificat qui prouve qu’il est bien celui qu’il prétend être. Votre navigateur accepte ce certificat dès lors qu’il est signé par une autorité de certification qu’il connait, tout comme on accepte la clé publique d’un utilisateur dès lors qu’elle est signée par une personne en qui on a confiance. Là encore l’autorité de certification est à la base de la sécurité.
L’authentification consiste à vérifier l’identité du correspondant. Lorsqu’on regarde le champs From d’un mail on identifie le correspondant (peut-être en se trompant). S’il a signé le mail avec sa clé privée, et qu’on a confiance en sa clé publique, alors on peut vérifier qu’il est bien celui qu’il prétend être et donc l’authentifier.
Pour le mail comme pour le web, l’authentification passe par la garantie que la clé publique que l’on possède est la bonne. Puisqu’il n’est pas toujours aisé de donner main dans la main cette clé ou son condensat, un autre système a été conçu : la certification.
La certification consiste à demander à un organisme reconnu d’offrir la garantie que le document27 récupéré sur Internet est bien celui de notre correspondant. Pour cela l’organisme ajoute au document sa signature à l’aide de sa clé privée. Ainsi toute personne qui a la clé publique de l’organisme peut vérifier que la signature est bonne. On voit qu’on a seulement repoussé le problème puisque maintenant pour savoir si un document est le bon, il faut récupérer la clé publique de l’organisme.
Les autorités de certification sont ces organismes reconnus et leur clé publique sont intégrées par défaut sur tous les ordinateurs. Ainsi la personne qui désire falsifier une clé publique doit maintenant commencer par trafiquer les systèmes d’exploitation des ordinateurs pour y mettre de fausses clés publiques d’autorité de certification. La tâche est nettement plus ardue.
De nombreuses entreprises sont des autorités de certification28. Elles bénéficient d’un marché très lucratif puisque signer la clé d’une personne est une opération dont le seul coût est la vérification de son identité. On retrouve l’une des nombreuses “poules aux œufs d’or” qui se promènent sur Internet29.
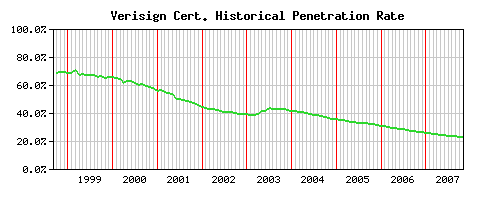
L’autorité de certification la plus importante, en part de marché, est Vérisign30.
Nom oct 2006 oct 2007 nombre % nombre % Verisign 77,357 26.33 81,612 22.26 Equifax (Geotrust) 61,498 20.93 81,417 22.20 Thawte 41,439 14.10 47,134 12.85 Comodo Limited 14,838 5.05 30,149 8.22 Starfield Technologies, Inc. 12,375 4.21 12,768 3.48
Tableau 1.2: Nombre de sites web certifiés et part suivant l’autorité de certification source : Security Space, 2007
Cependant aujourd’hui Verisign ne domine plus ce marché comme autrefois :
Figure 1.22: Part de marché de Verisign en tant qu’autorité de certification source : Security Space, 2007
|
Qui certifie ce site web ?
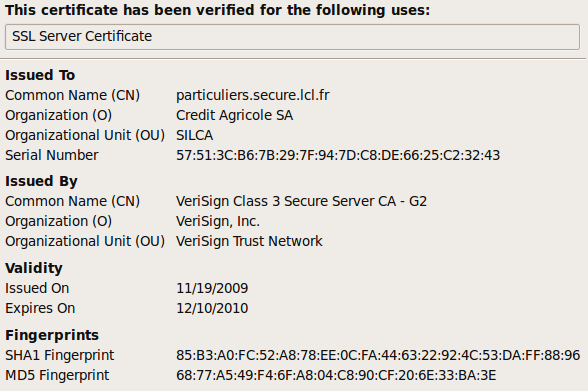
L’équivalent du champs From: pour identifier les sites web est leur adresse ou URL. On imagine que www.lcl.fr appartient à au Crédit Lyonnais (presque vrai, à sa maison mère) mais là encore il s’agit d’une information qui peut être trompeuse. Ainsi que penser de www.lcl.net ou particuliers.secure-lcl.fr ? Aussi le web dispose avec SSL d’un outil qui permet ce certifier qui est derrière un site web.
Là encore on se base sur la signature de la clé publique par une autorité de certification supérieure. Ainsi on peut voir dans le certificat du site du Crédit Lyonnais (lcl) qu’il est certifié par le Crédit Agricole, sa maison mère, qui elle-même est certifiée par Vérisign Class 3 Secure Server laquelle est certifiée par Vérisign Class 3 Primary. Enfin cette dernière est certifiée par elle-même, il faut bien s’arrêter quelque part. % openssl s_client -connect particuliers.secure.lcl.fr:443
CONNECTED(00000003)
depth=2 /C=US/O=VeriSign, Inc./OU=Class 3 Public Primary Certification Authority
verify error:num=19:self signed certificate in certificate chain
verify return:0
---
Certificate chain
0 s:/C=FR/ST=Hauts de Seine/L=La Defense/O=Credit Agricole SA/OU=SILCA/\
CN=particuliers.secure.lcl.fr
i:/C=US/O=VeriSign, Inc./OU=VeriSign Trust Network/OU=Terms of use at\
https://www.verisign.com/rpa (c)05/CN=VeriSign Class 3 Secure Server CA
1 s:/C=US/O=VeriSign, Inc./OU=VeriSign Trust Network/OU=Terms of use at\
https://www.verisign.com/rpa (c)05/CN=VeriSign Class 3 Secure Server CA
i:/C=US/O=VeriSign, Inc./OU=Class 3 Public Primary Certification Authority
2 s:/C=US/O=VeriSign, Inc./OU=Class 3 Public Primary Certification Authority
i:/C=US/O=VeriSign, Inc./OU=Class 3 Public Primary Certification Authority
---
|
Étant donné que la signature électronique est reconnue par la loi française, il semblerait normal que l’État certifie les signatures des citoyens après les avoir duement vérifiées comme il le fait pour les cartes d’identité. Et bien non, l’État délaisse l’identité numérique au secteur privé. Il n’est pas possible d’aller au commissériat de police avec sa clé publique et demander qu’elle soit certifiée.
L’État demande aux entreprises de payer la TVA par Internet. Pour cela il leur demande de justifier leur identité en présentant leur certificat numérique certifié par une autorité de certification. Et pour être bien clair, le ministère des finances indique dans sa FAQ sur la TéléTVA que
Les autorités de certification font autorité pour certifier les identités et principales caractéristiques des personnes à qui elles délivrent des certificats numériques. Elles jouent un peu le même rôle que les mairies lorsque vous faites une demande de passeport.
et ajoute
(le) Ministère de l’Economie, des Finances et de l’Industrie qui en les référençant, reconnaît la qualité des procédures mises en œuvre dans l’identification des demandeurs, l’enregistrement et la délivrance des certificats. C’est la raison pour laquelle elles sont amenées à vous demander de nombreux justificatifs.
On voit que dans ces deux cas où l’internaute veut ou doit justifier son identité, il ne peut le faire qu’en passant par une entreprise privée qui sera amenée à demander de nombreux justificatifs, justificatifs qu’un citoyen n’a peut-être pas envie de donner à une entreprise privée. Ce point est d’autant plus triste que la carte d’identité électronique nationale serait très utile sur Internet pour réduire les risques d’arnaques, diminuer le nombre de spam, communiquer avec l’administration, vérifier l’âge des Internautes et peut-être un jour faire de la démocratie électronique à visage ouvert.
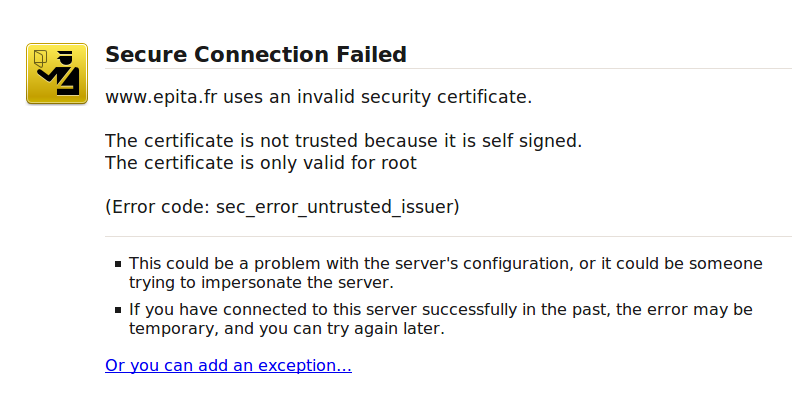
Puisque la certification est nécessaire dans certains cas, comme pour avoir un site Web sécurisé, et que les seules autorités de certification sont payantes, de nombreuses personnes s’auto-certifient à savoir qu’elles signent leur propre clé privée ou créent leur autorité de certification pour l’occasion. Dans tous les cas la clé ne sera pas reconnue puisque l’autorité n’est pas référencée mais cela répond à l’obligation initiale. Le résultat est que le navigateur qui arrive sur une page web chiffrée par une clé auto-certifiée va bloquer tant que l’utilisateur ne lui indique pas de passer outre. Une démarche que fait l’utilisateur sans plus rien vérifier, à juste titre, mais qui finalement affaiblit l’ensemble des protections.
Figure 1.24: Firefox bloque un site web auto-certifiée
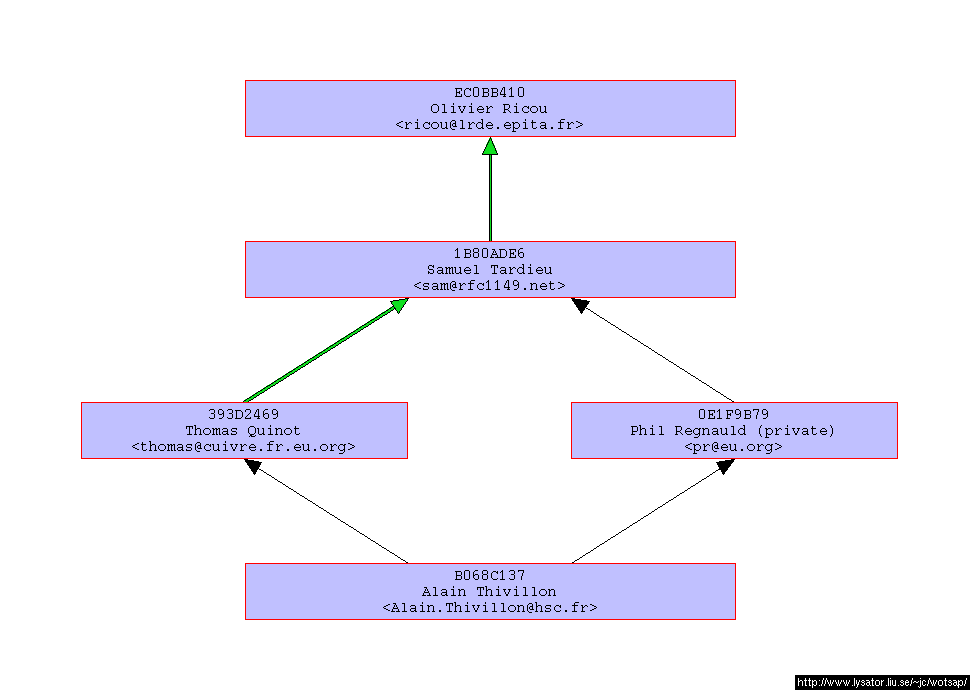
La dernière solution pour certifier sa clé privée revient à la faire signer par le plus de personnes qu’on connait directement. Si ces personnes sont elles-mêmes connues d’autres personnes (cas probable), alors rapidement toute personne pourra vérifier votre clé sachant qu’elle fait confiance aux intermédiaires. Bien sûr cela demande que chacun fasse son travail de certification sérieusement et refuse de signer une clé sans une vérification physique (une clé envoyée par mail n’est pas assez sûre pour qu’on accepte de la certifier). Il est aussi possible de signer en indiquant un certain niveau de confiance (dans le dessin ci-dessous les flèches en noir offrent moins de confiance que celles en vert).
Figure 1.25: Chaîne de signatures de clés source : Wotsap
Ce système est appelé le réseau de confiance (Web of trust en anglais).
Pour finir ce chapitre, regardons comment on casse un algorithme de cryptographie :
Il y a donc deux catégories : les failles et la force brute qui teste toutes les clés possibles.
La longueur d’une clé est la seule protection contre cette attaque. Ainsi suivant les caractères que vous utilisez, l’alphabet, et la longueur de votre mot de passe, tester toutes les clés possibles est raisonnable ou non. Le tableau ci-dessous en donne une idée :
Alphabet 4 caractères 8 caractères 12 caractères Lettres minuscules 264 = 456 976 208 × 109 954 × 1015 Lettres minuscules et chiffres 364 = 1,6 × 106 2 × 1012 4 × 1018 Minuscules, majuscules et chiffres 624 = 14 × 106 218 × 1012 3 × 1021
Tableau 1.3: Nombre de clés possibles suivant l’alphabet et la longueur
Si on suppose qu’on a un ou des ordinateurs qui peuvent tester un million de clés par seconde (chiffre très raisonnable) alors on voit qu’une clé de 4 caractères résiste au mieux 14 secondes. Par contre la clé de 12 caractères avec minuscules, majuscules et chiffres résistera un million de siècles...
DES a une clé de 56 bits32. Il a été l’une des premières victimes cassées par la force brute :
distributed.net le casse en 39 jours avec
10 000 ordinateurs et une moyenne
de 28.1 milliards de clés testées par jour.
Electronic Frontier Foundation, EFF le casse avec
une machine à 250 000 $ fabriquée pour en 3 jours,
distributed.net.
Dans le dernier cas, près de mille milliards de clés étaient testées par secondes. A ce rythme, la clé de 12 caractères avec minuscules, majuscules et chiffres n’aurait tenu qu’un siècle. Sachant que la puissance des ordinateurs double tous les deux ans33, cela veut dire que dix ans plus tard, la même clé ne résisterait plus que 3 ans.
Cela étant, tester une clé de type DES peut prendre moins de temps que de tester une clé de taille égale d’un autre algorithme, aussi il est important de faire attention aux comparaisons.
La force brute est une méthode qui se répartie très bien sur un ensemble d’ordinateurs, chacun testant une partie des clés. Aussi des internautes ont créé une organisation chargée de répartir le travail parmi les ordinateurs mis à leur disposition, c’est distributed.net.
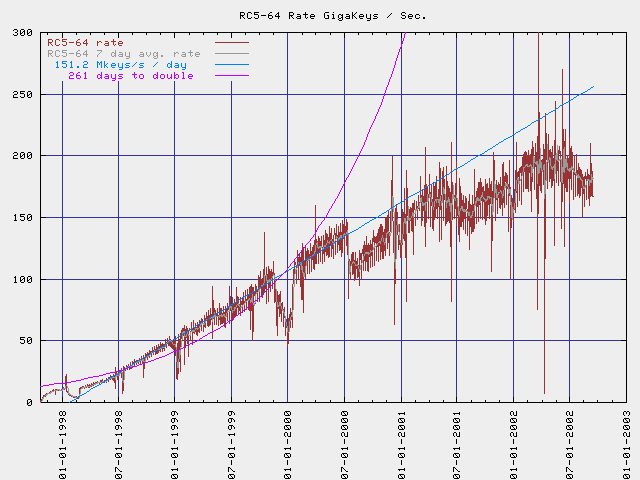
Avec cette méthode, le RC5 a été régulièrement cassé avec des clés de plus en plus longues :
1 757 jours de calcul, environ 4 ans et 10 mois
331 252 participants
15 769 938 165 961 326 592, 15 milliards de milliards de clés testées
soit 81% des clés possibles
vitesse maximale : 270 147 024 000 clés/seconde
- soit 32 000 de Apple PowerBook G4 800MHz ou
46 000 PC AMD Athlon XP 2Ghz travaillant en parallèle
- à cette vitesse il suffirait de 790 jours pour tester
l'ensemble des clés
Figure 1.26: Vitesse de test des clés RC5-64 durant le calcul
L’algorithme de cryptographie du Web est SSL. Dans les années 90 et encore au début des années 2000, cf tableau 1.1, il se conjuguait en 3 variantes de longueur de clés différentes : SSL 40 bits, SSL 56 bits et SSL 128 bits. Et poutant dès l’été 1995, SSL 40 bits a été cassé en 32 heures à l’INRIA et en 3h30 durant l’été 1997 à Berkeley.
Aujourd’hui quelques minutes voire quelques secondes suffiraient aussi il est indispensable d’utiliser la méthode SSL 128 bits. Heureusement il ne doit plus exister de sites qui utilisent encore SSL 40 ou 56 bits.
Il existe heureusement peu de cas où des avancées mathématiques cassent des algorithmes de cryptographie.
Il existe un concours ouvert dont le but est de casser un message chiffré avec RSA. Le but est de trouver les deux nombres premiers p et q qui génèrent le module de l’algorithme de RSA ce qui permet d’avoir la clé privée. Pour venir à bout de ce défi, la méthode mathématique utilisée est celle du “crible algébrique” qui permet de ramener le problème à un calcul matriciel dont la résolution nécessite un super ordinateur34. Ainsi
On prédit la chute de RSA 1024 bits pour 2012, aussi il est temps d’utiliser des clés plus longues.
Depuis 2004 on sait qu’il est possible de faire deux messages qui ont le même condensat MD5. En 2008, une équipe de chercheurs35 a appliqué cette possibilité théorique à un cas bien pratique : la génération de faux certificats Web.
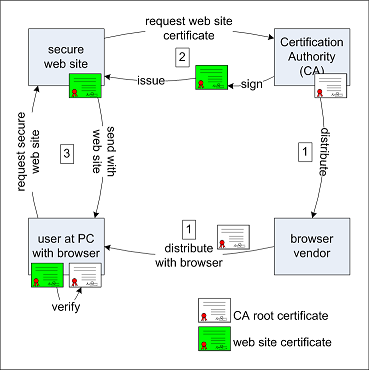
En temps normal un site web sécurisé envoie au navigateur un certificat qui prouve qu’il est bien le site web qu’il prétend être, cf figure 1.27. Le navigateur vérifie l’identité du site Web en vérifiant que le certificat qu’on lui envoie est bien signé par une autorité de certification connue (c.a.d. dont la clé publique est dans le navigateur). Si c’est le cas, il ne reste plus qu’à vérifier que les données écrites sur le certificat, comme l’URL, correspondent à celles du site web qu’on est en train de visiter. Tout ce travail est invisible pour l’utilisateur si tout se passe bien.
Figure 1.27: Signature et utilisation normale des certificats SSL
Dans le cas normal, l’utilisateur (en bas à gauche) vérifie le certificat du site web (en haut à gauche) avec la clé publique de l’autorité de certification (en haut à droit) qui lui a été fournie avec son navigateur (en bas à droite).
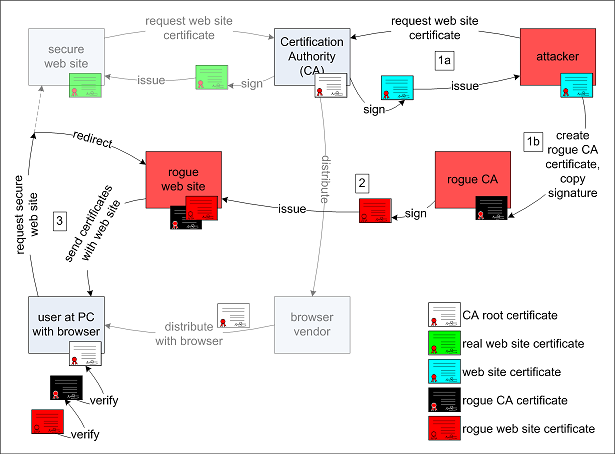
Figure 1.28: Introduction d’un faux certificat SSL
L’attaque, cf figure 1.28, consiste à demander à l’autorité de certification de nous signer un certificat (le bleu). La signature étant faite sur le condensat MD5 du certificat, elle sera aussi valable si elle est attachée à un autre document qui a le même condensat que le certificat qu’on a envoyé. Cet autre est ici la clé publique de notre fausse autorité de certification (la noire). Avec cette fausse autorité, on peut signer le certificat de notre faux site web (le rouge). Maintenant il ne reste plus qu’à intercepter les requêtes vers le site web d’origine (en haut à gauche) et à lui présenter le certificat rouge du faux site accompagné de celui de la fausse autorité de certification (le noir). Ainsi le navigateur constate que le site a un certificat (le rouge), que ce certificat est signé par le noir lequel est signé par le certificat officiel de l’autorité de certification (puisque le noir a le même condensat que le bleu). Donc tout va bien et aucun avertissement ne sera envoyé à l’utilisateur qui se connectera au faux site web en toute confiance puisque la connexion est sûre grâce à SSL.
Depuis l’annonce de cette faille, les autorités de certification sérieuses n’utilisent plus le condensat MD5. Cela peut être vérifié en regardant l’algorithme de signature utilisé dans la description du certificat.
En mai 2008 la distribution Debian de Linux doit annoncer que toute la sécurité basée sur OpenSSL est compromise. Quelques années auparavant, une personne en charge de faire marcher le logiciel OpenSSL sur Debian a retiré du code source des lignes qui semblaient ne servir à rien. Et si le fait de retirer ces lignes n’a rien modifié au fonctionnement du logiciel, cela a détruit la fonction aléatoire en charge de fournir les nombres de base pour générer les clés. Or si on peut deviner ces nombres de base, on peut aussi deviner les clés, donc toute la sécurité s’effondre.
Figure 1.29: Fonction aléatoire d’après XKCD
Moralité : la programmation de la cryptographie est réservée aux spécialistes. Il est illusoire d’espérer programmer un algorithme de cryptographie sans générer des failles de sécurité si on n’a pas une longue expérience dans le domaine.
Les passionnés pourront consulter en anglais CircleID, http:/www.circleid.com/.
La faille humaine est la grande faiblesse de la sécurité informatique contre laquelle chacun peut lutter :
Pour les informaticiens ou passionnés, quelques sources hétéroclites :
En ce qui concerne la cryptographie, on pourra aussi consulter les ouvrages suivants : The Codebreakers de David Kahn, cf [], et l’Histoire des codes secrets de Simon Sing, cf [].
Certains manuels (livres) sont disponibles en ligne dont The Handbook of Applied Cryptography, cf [], les Frequently Asked Questions About Today’s Cryptography des RSA Labs, cf [].
Enfin, les sites suivants contiennent des informations intéressantes :



{kind=link}